Project
Identity Customization

EditID: Training-Free Editable ID Customization for Text-to-Image Generation
EditID introduces a training-free, feature-decoupling framework for editable identity customization on Flux text-to-image generation. By splitting the reference image into identity features and bias features and re-injecting them at controlled positions in the DiT backbone, EditID severs the long-standing zero-sum trade-off between identity fidelity and prompt editability without any per-subject fine-tuning. Achieves SOTA on the self-built IBench benchmark and was accepted to Findings of EMNLP 2025.

EditIDv2: Editable ID Customization with Data-Lubricated ID Feature Integration
EditIDv2 extends the EditID framework with a data-lubrication mechanism for ID feature integration. Beyond v1's training-free decoupling, v2 introduces data-lubricated injection that significantly improves data efficiency and reduces drift on long prompts, generalising EditID to high-complexity narrative scenes. Accepted to Multimedia Systems (2026).

DVI: Disentangling Semantic and Visual Identity for Training-Free Personalized Generation
DVI separates semantic identity (who the person is) from visual identity (how they look) in the reference image, then routes the two streams through different attention pathways during inference. This decomposition gives fine-grained control over how much semantic vs visual content is transferred, and works as a drop-in training-free module for text-to-image personalisation.

FlexID: Training-Free Flexible Identity Injection via Intent-Aware Modulation
FlexID introduces an intent-aware modulation gate that dynamically routes identity-injection signals across spatial regions of the text-to-image diffusion latent. The gate is conditioned on the prompt and reference image to decide where in the canvas identity features should dominate, enabling flexible identity placement for single- and multi-subject prompts without any training.

Inject Where It Matters: Spatially-Adaptive Identity Preservation
Identifies the prompt-aligned tokens during cross-attention and restricts identity-feature injection to those tokens only, preventing identity leakage into the background. The result is sharper identity preservation in the subject region without contaminating scene context, all training-free.
Image Editing on Diffusion Transformers

Dual-Channel Attention Guidance for Training-Free Editing Control on DiT
Training-free image editing control for Diffusion Transformers via dual-channel attention guidance. Splits the editing signal across a content-preserving channel and an edit-driving channel and injects them through separate attention pathways in the MMDiT backbone, giving precise control over edit strength without any retraining.

AdaEdit: Adaptive Temporal and Channel Modulation for Flow-Based Image Editing
AdaEdit performs flow-based image editing by adaptively modulating the temporal trajectory and per-channel scaling of the flow-matching ODE. Without any fine-tuning, users can dial in edit strength and edit type while keeping unedited content intact.

Edit Spillover as a Probe: Do Image Editing Models Implicitly Understand World Relations?
Treats image-editing models as probes for visual world knowledge. By systematically perturbing edits that should propagate to related objects, the work measures whether MMDiT / Flux editing models implicitly understand object relations, physics, and counterfactual scene structure — a diagnostic complement to standard fidelity metrics.

AttnRouter: Per-Category Attention Routing for Training-Free Editing on MMDiT
Per-category attention routing for training-free image editing on MMDiT. Routes attention computation through different paths for object vs background vs text regions, allowing category-aware edit control with no additional training and minimal compute overhead.
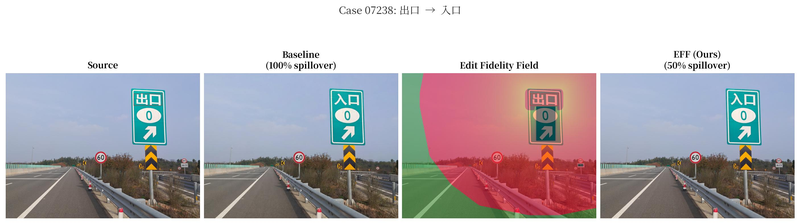
Edit Fidelity Field: Semantics-Aware Region Isolation for Scene Text Editing
Training-free scene text editing via a semantics-aware Edit Fidelity Field. Locally constrains edits to text regions and preserves stylistic consistency with surrounding image content, drastically reducing the spillover artefacts that plague baseline DiT editors on dense scene text.

PhysEdit: Physically-Consistent Region-Aware Image Editing
Physically-consistent region-aware image editing via adaptive spatio-temporal reasoning. PhysEdit reasons about physical plausibility (shadows, reflections, occlusions) when applying edits, ensuring that the edited region remains consistent with scene physics rather than producing locally-correct but globally-implausible outputs.
Diffusion Inference Acceleration

LayerCache: Layer-wise Velocity Heterogeneity for Efficient Flow Matching Inference
Exploits layer-wise velocity heterogeneity in flow-matching inference: different transformer layers exhibit different rates of feature change across timesteps, so the slow-changing layers can be cached and reused across multiple timesteps. Cuts inference cost on flow-based image and video generation with no measurable quality loss.

Frequency-Aware Error-Bounded Caching for Accelerating Diffusion Transformers
Frequency-aware caching for DiT inference. Decomposes feature changes by frequency band and only refreshes the high-frequency components per step, with provable per-step error bounds. Drops FLOPs on DiT inference while keeping output quality within a guaranteed envelope.

FastUSP: Multi-Level Collaborative Acceleration for Distributed Diffusion Inference
Multi-level collaborative acceleration framework for distributed diffusion model inference. Combines sequence parallelism, parameter sharding, and dynamic load balancing to scale Flux / DiT inference across multiple GPUs with near-linear speedup.
Hyperspectral Image Classification

MVNet: Hybrid Mamba-Transformer Vision Backbone for HSI Classification
Combines Mamba's linear-time long-range modelling with local Transformer attention to handle the high spectral dimensionality of hyperspectral cubes efficiently. The hybrid backbone outperforms pure Transformer and pure 3D-CNN baselines on Indian Pines, Pavia U., and Salinas under small-sample regimes.

STNet: Transformer-based Spectral-Spatial Attention Decoupling with Adaptive Gating
Separates the spectral and spatial reasoning paths into two independent attention streams and gates their fusion adaptively per-token, improving classification on small-sample HSI scenes. Published in International Journal of Image and Data Fusion.
KANet: Dynamic 3D KAN Convolution with Adaptive Grid Optimization
Replaces standard 3D convolution kernels with Kolmogorov-Arnold Network units whose grid points adapt to local spectral-spatial statistics. Boosts both accuracy and parameter efficiency on HSI classification. Published in Arabian Journal for Science and Engineering.

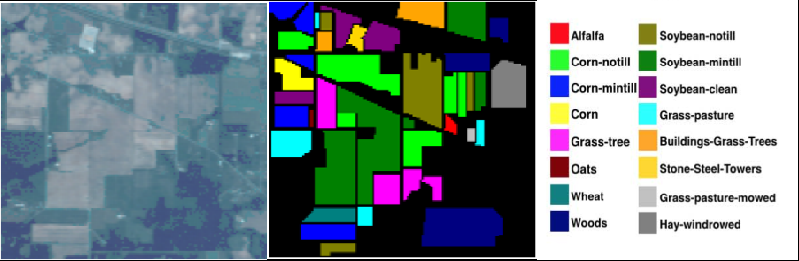
EKGNet: Expert Kernel Generation Network Driven by Contextual Mapping
Generates classification kernels conditioned on local context features rather than relying on a fixed kernel bank. Improves small-sample generalisation by adapting the receptive field to the local hyperspectral signature.
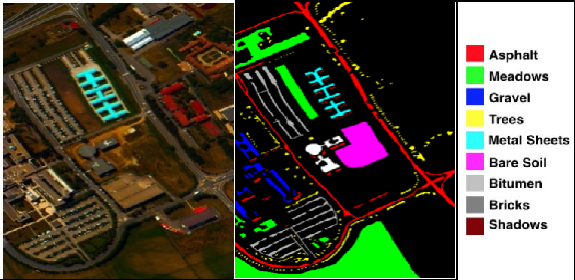
SGDSCNet: Spatial-Geometry Enhanced 3D Dynamic Snake Convolution
Adapts Dynamic Snake Convolution (originally proposed for tubular structures) to hyperspectral cubes, letting the kernel deform along elongated spectral signatures. Geometric prior gives better discrimination on linear class boundaries.

Suning AIGC Platform

Suning AIGC Platform
Provides AIGC services including image/video generation based on diffusion models and LLMs, covering model photo / product photo / poster image / anime avatar generation, controlled-ID type generation, marketing short-video generation for combination fission, lip-sync digital humans for e-commerce live streaming, face swapping, and script generation for voice-over marketing.
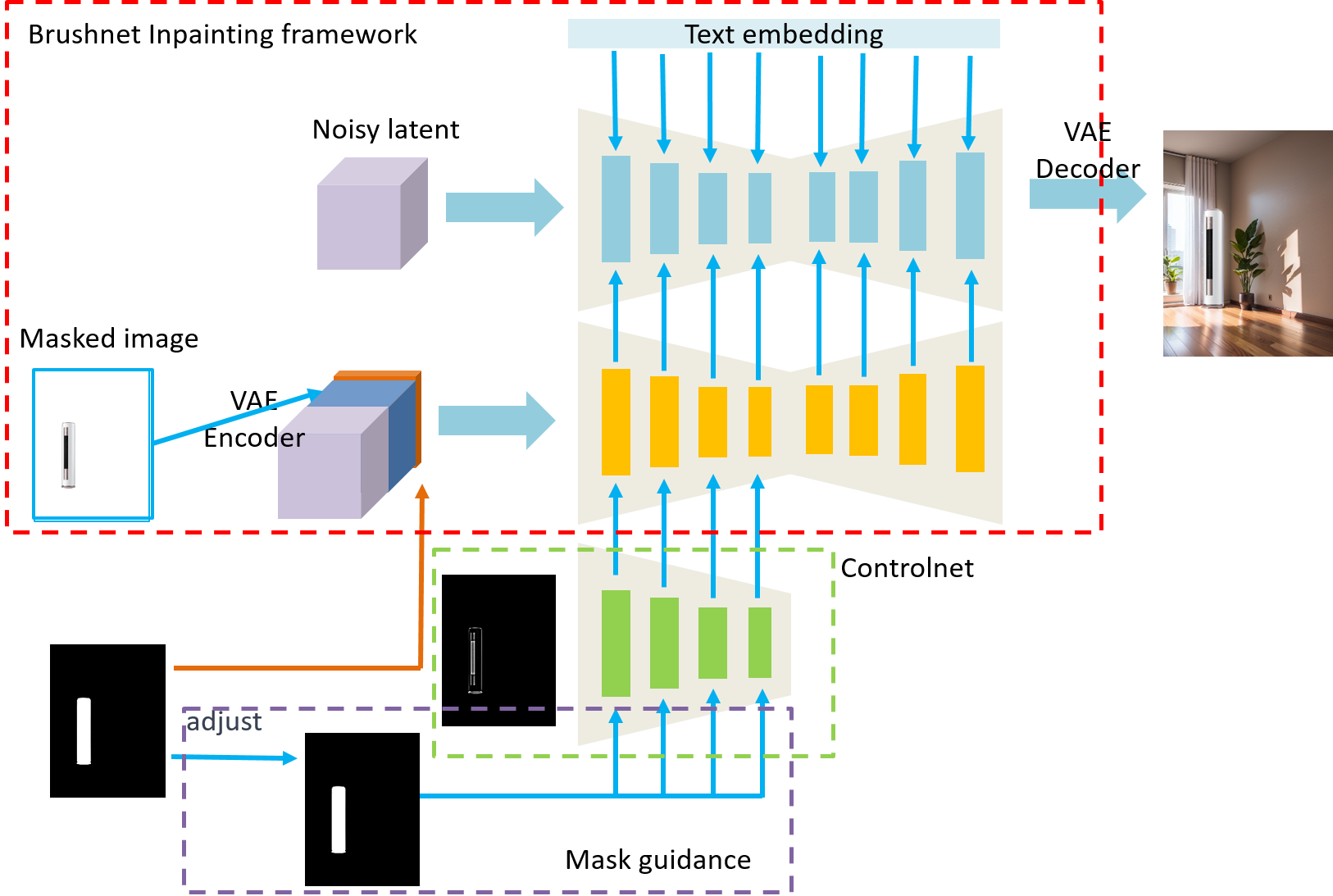
E-Commerce Inpainting with Mask Guidance in ControlNet
E-commerce image generation has long been a core demand, with the goal of restoring the missing background while preserving the foreground product. This work addresses overcompletion — the difficulty in maintaining product features under diffusion-model inpainting — via two solutions: (1) an instance-mask fine-tuned inpainting model and (2) a train-free mask-guidance approach that introduces refined product masks as constraints when combining ControlNet with UNet, preventing the model from over-rebuilding the main product.
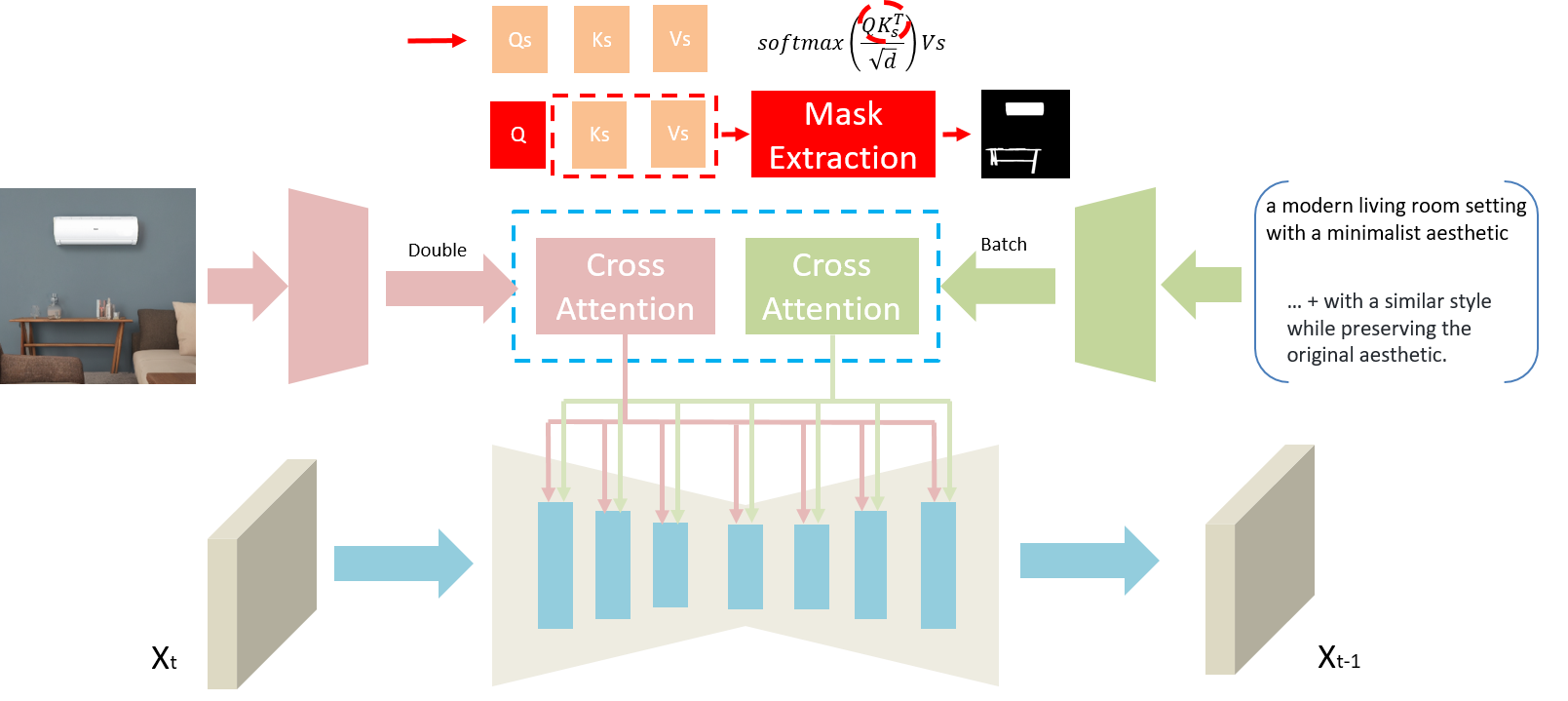
Training-Free Style-Consistent Image Synthesis with Condition & Mask Guidance
Train-free framework for style-consistent e-commerce image generation. Operates at the QKV level inside attention (self- and cross-attention), using shared KV to amplify similarity in cross-attention and using attention maps to generate mask guidance that steers style-consistent generation while preserving the product's main composition.
Intelligent Creative Platform
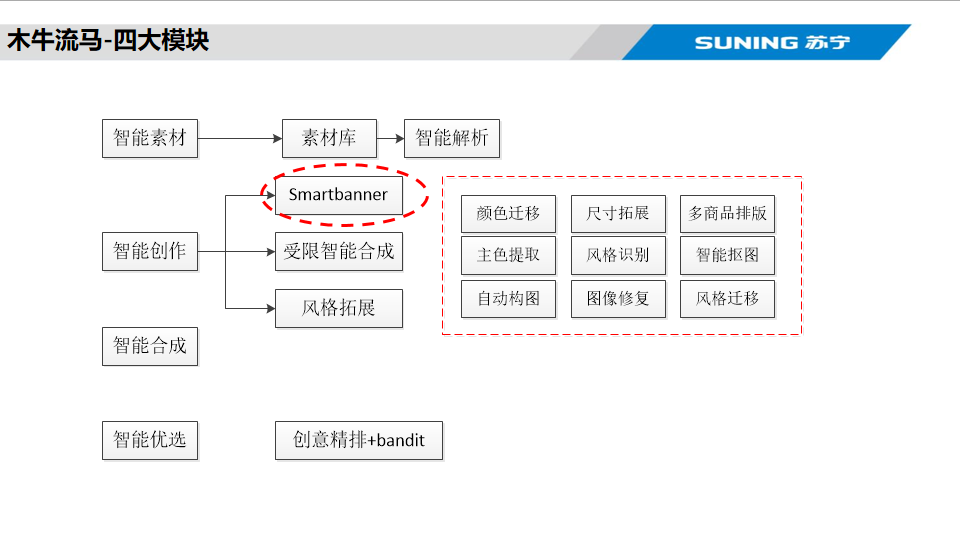
Iwogh Platform (木牛流马)
Iwogh is Suning's internal creative design platform with three core modules: intelligent parsing, intelligent creation, and intelligent optimization, plus a set of real-time creative tools. One of China's earliest intelligent creative production platforms, benchmarked against Alibaba 鹿班 and JD 羚珑.
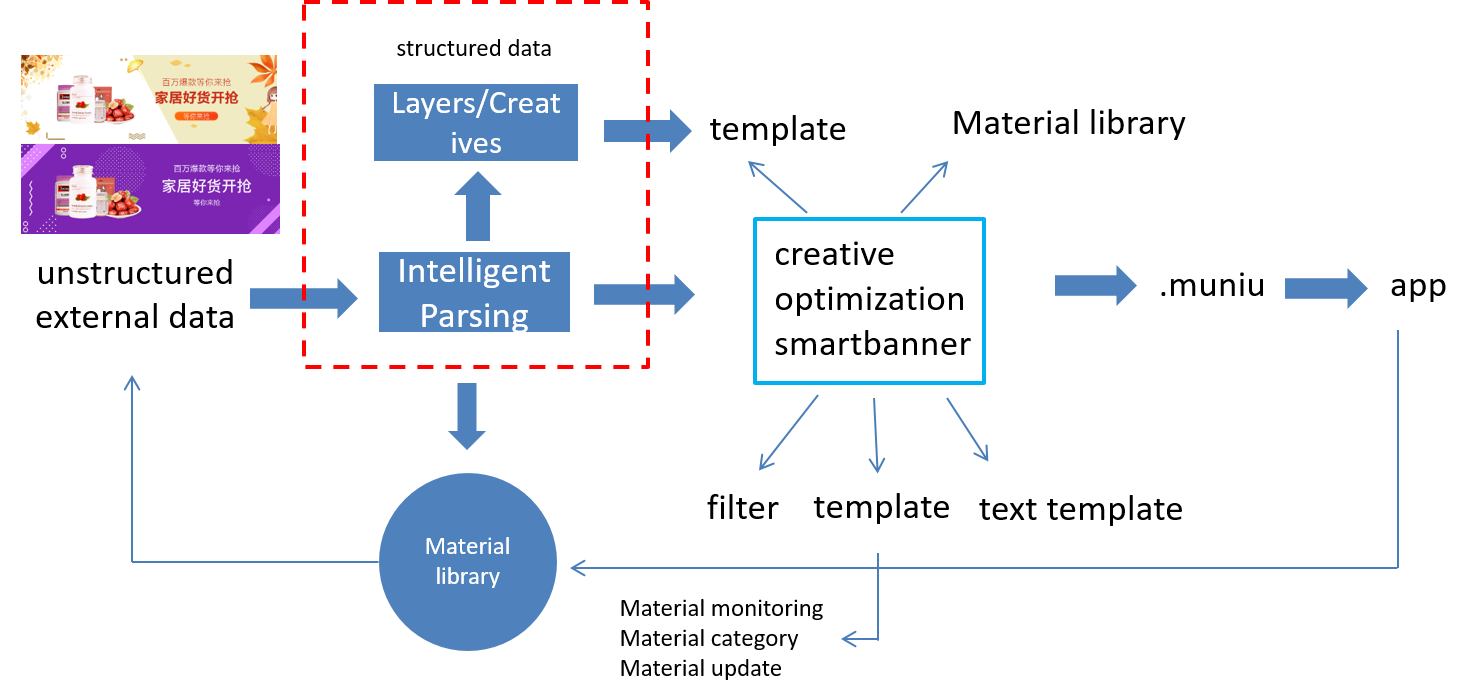

Intelligent Parsing
Automated framework for parsing creative materials (banners, posters, designer manuscripts) into structured design semantics. Comprises material recognition, preprocess, smartname, and label layers — using detection (Cascade RCNN, GFL), layer-level filtering, intelligent naming, and multi-level tagging. Significantly boosts downstream intelligent creation and creative optimization in Suning's production scenarios, lifting creative material exposure, circulation, and click-through rates.
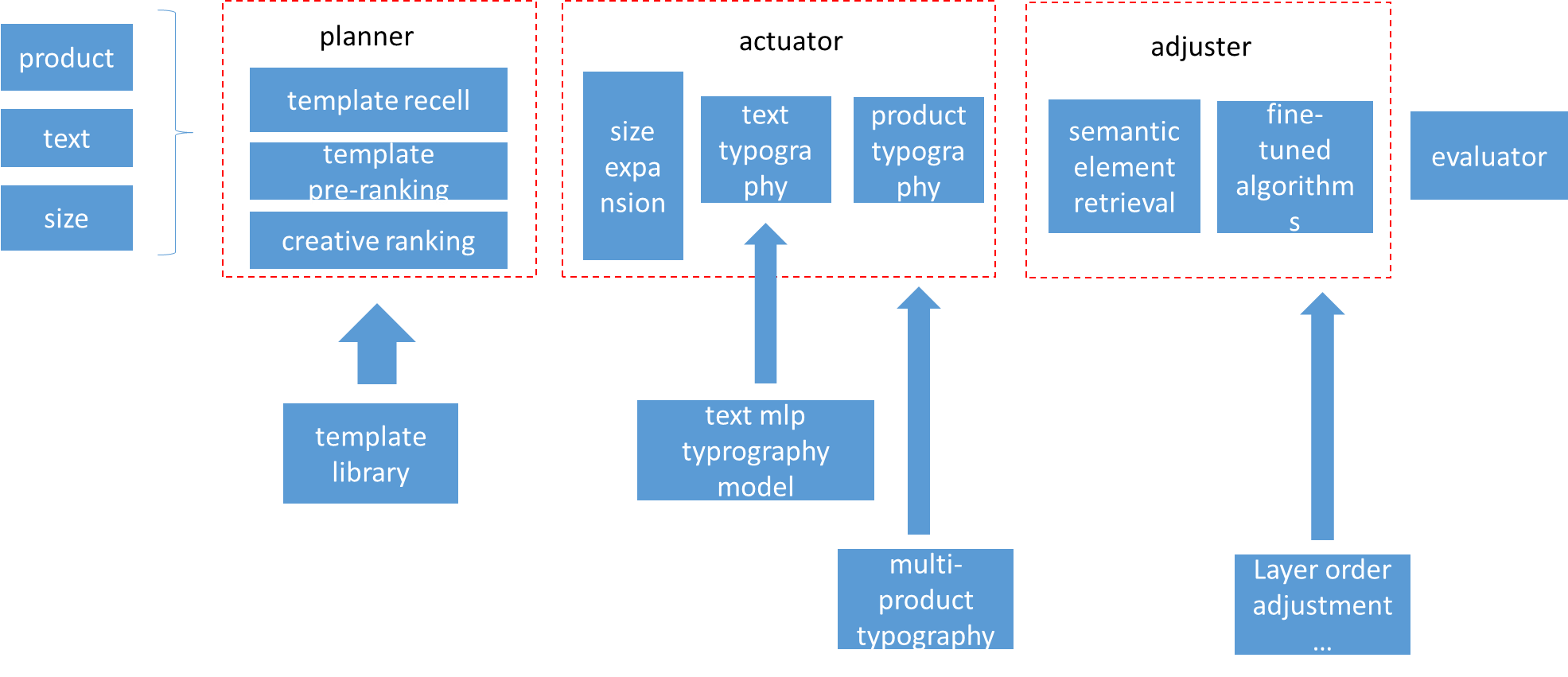
Smartbanner
Intelligent banner design framework that balances creative freedom against design rules. With only product, copy and size as inputs, Smartbanner's planner / actuator / adjuster / generator pipeline synthesizes high-freedom, design-compliant banners. Deployed at production scale, lifting CTR by 30%, designer efficiency by 500%, and synthesizing hundreds of millions of images annually.


ADCT — Dynamic Creative Optimization under Sparse/Ambiguous Samples
Two-stage cascade for ad-creative CTR estimation under sparse and ambiguous samples. Stage 1: autoco-based ranking + a transformer-based rerank trained with rank-distillation soft labels to extract creative order knowledge and link ambiguous samples to positive/negative pairs. Stage 2: a bandit selects from Stage 1's top-N for live serving. Online A/B testing shows +10% CTR vs baseline.
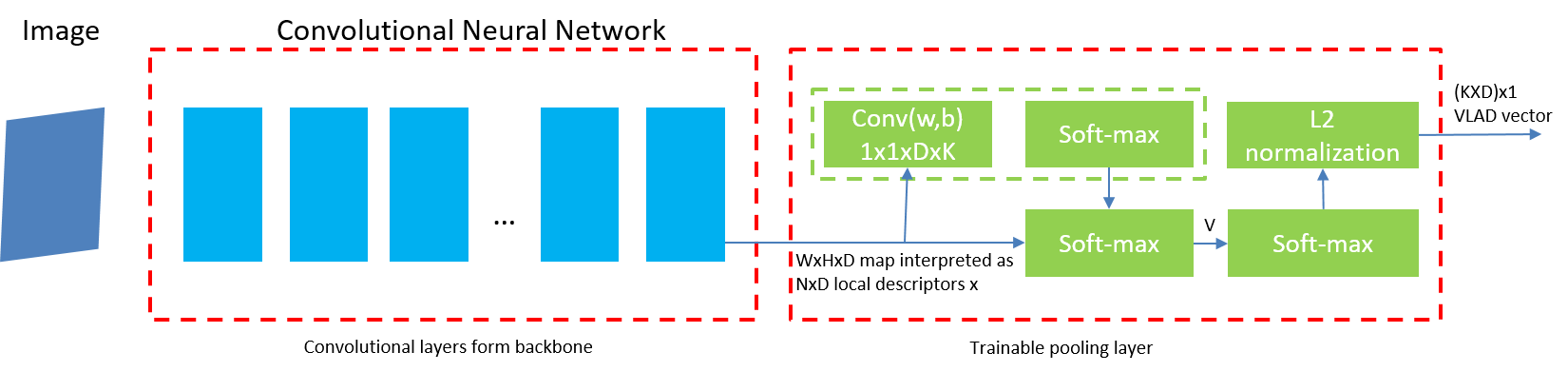
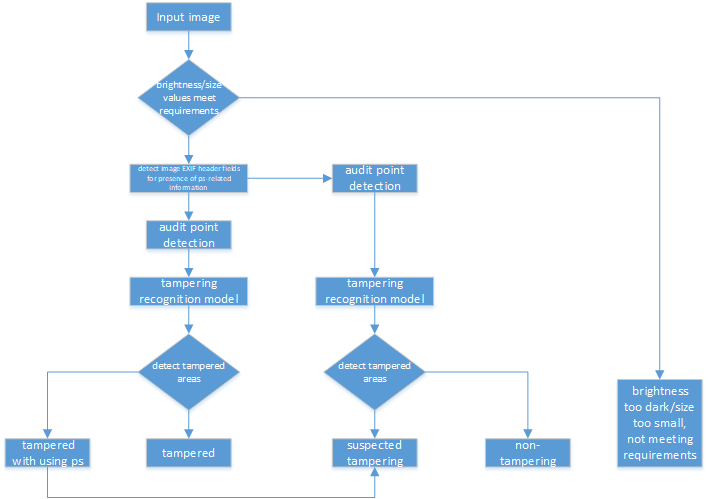
PS Tamper Detection
Three-step pipeline (feature-assist, audit-point localization, tamper recognition) for document Photoshop-tamper detection with graded output (tampered / suspected / untampered). Uses EXIF + binary-stream + noise feature assistance, detection frameworks for localization, and a dual-path dual-stream (RGB + ELA) recognition network with self-correlation percentile pooling and NetVLAD fusion. Accuracy 0.804 on internal benchmarks; saved Suning RMB 3M+/year.